「嘿,連恩,」我說:「你曾經去過戈壁沙漠嗎?就是大興安嶺再向西走一段距離那邊。」
「有啊,那邊怎麼了嗎?」
「嗯,你知道在那兒逐水草而居的草泥馬嗎?就是春天萬物生長的時候會在那兒的大草坪上翻滾跳躍那群草泥馬啊?你有沒有聽過,在冬季草木不生的時候,那群草泥馬會遷徙到哪裡呢?」
「什麼東西遷徙到哪兒?」
「草泥馬啊,你清楚嗎?」~節錄自《賴田捕手》第十二章
昨天我們認識了 LINE 提供的應用程式編程介面,知道如何透過 Heroku 提供的工作日誌來觀察應用程式的工作狀況,並且成功的改善了 LINE 聊天機器人。學了這麼多有趣的東西、對寫程式越來越熟悉的你,怎麼會滿足於做出一個回音機器人呢?今天我們就來認識更多的應用程式編程介面、寫更多的程式吧!
先來看看我們已經會的。我們用 reply_message 讓我們的 LINE 聊天機器人懂得有人說話要回覆,回覆的方法則用TextSendMessage寫成。加上一點巧思,我們的 LINE 聊天機器人不僅可以學人說話,還可以邊說話邊哼著旋律,真可愛。
不過呢,相信大家都聽過流傳在批踢踢上面的一句名言:發文不附圖,此風不可長➀。大家不知道的是,其實在草泥馬的圈子裡,也流傳著一句類似的話:回文不回圖,此風不可長。與其使用文字,草泥馬們更喜歡看圖,小小一張圖片,畫中有話、意涵豐富、賦予草泥馬們無限想像,可謂勝過千言萬語。
好喔,既然草泥馬們這麼要求,我們就來試著用 LINE 提供的另一個發送信息方式ImageSendMessage寫個使用圖片作為回覆的 LINE 聊天機器人吧。不過,要怎麼回圖呢?先來看看 LINE 提供的ImageSendMessage長什麼樣子吧➁:
image_message = ImageSendMessage(
original_content_url='https://example.com/original.jpg',
preview_image_url='https://example.com/preview.jpg'
)
LINE 提供的ImageSendMessage是靠統一資源定位器(uniform resource locator,白話一點就是網址)來傳送圖片,所以我們只能傳送網路上的圖片。再者,對於圖片的檔案大小也有限制(官方說明文件是 1MB➂)。既然這麼麻煩,大家心中是否都有一個答案了呢:找圖片、上Google!沒錯,我們就來用 Google 找到的圖片,當作我們的回覆吧!簡而言之,今天要來實作的,是一個可以幫你上 Google 抓圖片(當然是隨便抓)的 LINE 聊天機器人。
既然需要上 Google 找圖片,我們的 Python 檔案中就要有程式碼能夠跟網頁互動,讀取網頁上的資料。而 Python 內建的(沒錯又是內建的,所以不需要再安裝任何套件)套件統一資源定位器資料庫 (urllib) 就可以幫我們做到這件事。題外話,其實可能會有更多人選用請求 (requests) ➃ 這個套件來讀取網頁資料,不過統一資源定位器資料庫是內建的,不用安裝,也足夠幫我們達成今天的目標,所以我先介紹統一資源定位器資料庫。再一個題外話,怎麼突然講到網頁了呢?還記得我們的鐵人賽的主題是要從 LINE 聊天機器人走到網頁再走到資料視覺化吧?!因此今天就先利用這個機會,熟悉熟悉網頁的架構。
來看看urllib怎麼用:
In [1]: import urllib
In [2]: url = "https://www.google.com/"
conn = urllib.request.urlopen(url)
print(conn)
<http.client.HTTPResponse object at 0x0000024F6777A7C8>
利用urllib.request.urlopen來讓我們開啟指定的網址(此例為"https://www.google.com/")。不過我們究竟在做些什麼呢?還是看不出來。
In [3]: data = conn.read()
print(data)
b'<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="zh-TW"><head><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/logos/doodles/2019/rugby-world-cup-2019-opening-day-675365183710823…以下略
喔喔,原來我們已經在擷取網路上的資料啦。怎麼說呢?開個我們正在讀取的網址 "http://www.google.com/" 來瞧瞧。然後在空白處按右鍵,選擇檢視網頁原始碼,如圖一。如果你用的瀏覽器是 Chrome,按下 Ctrl + U 這個快捷鍵可以快速開啟一個寫滿了網頁原始碼的分頁,如圖二。
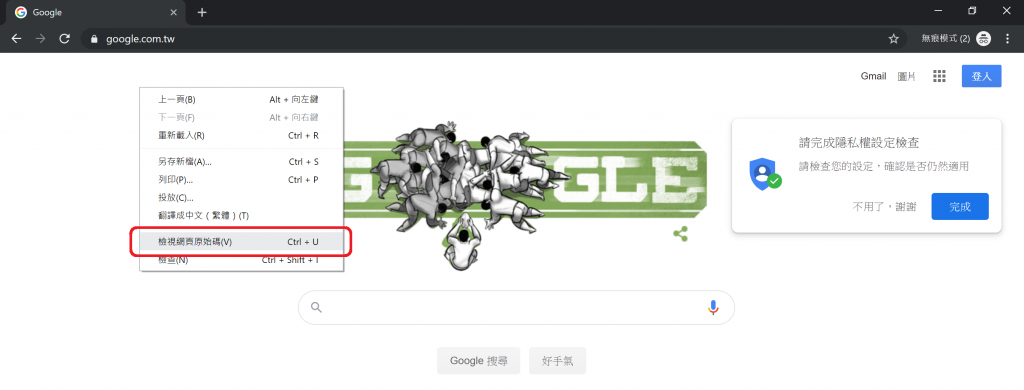
圖一、點選檢視網頁原始碼

圖二、網頁原始碼
仔細瞧瞧,這不就跟我們用 conn.read()得到到資料是一樣的嗎?再驚嘆一次:原來我們已經在擷取網路上的資料啦!順帶一提,我們現在看到像亂碼一樣的東西,其實是屬於 HTML 5 檔案格式的文件。
雖然現在這樣就已經很成功了,不過只用這個方法我們今天無法走到最後,所以再試個複雜一點的方法來截取網頁資料:
In [4]: url = "https://www.google.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
req = urllib.request.Request(url, headers = headers)
conn = urllib.request.urlopen(req)
接下來一樣:
In [5]: data = conn.read()
print(data)
b'<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="zh-TW"><head><meta charset="UTF-8"><meta content="origin" name="referrer"><meta content="/logos/doodles/2019/rugby-world-cup-2019-opening-day-6753651837108235-l.png"…以下略
這兩種方式有什麼不同呢?第一種方法,我們利用urllib.request.urlopen向目標網址發出請求。而第二種方法,我們在向目標網址發出請求的時候,利用header裡面的User-Agent同時表明了瀏覽器的身分➄。這是更萬全的作法。
現在我們已經可以用urllib.request.urlopen讀取指定網址內的資料了,那麼距離我們今天的目標,也就是上 google 抓圖片只剩下一步之遙了。首先,在 google 上搜尋個關鍵字,我們就胡亂選個邦幫忙,搜尋結果選擇為圖片,如圖三。
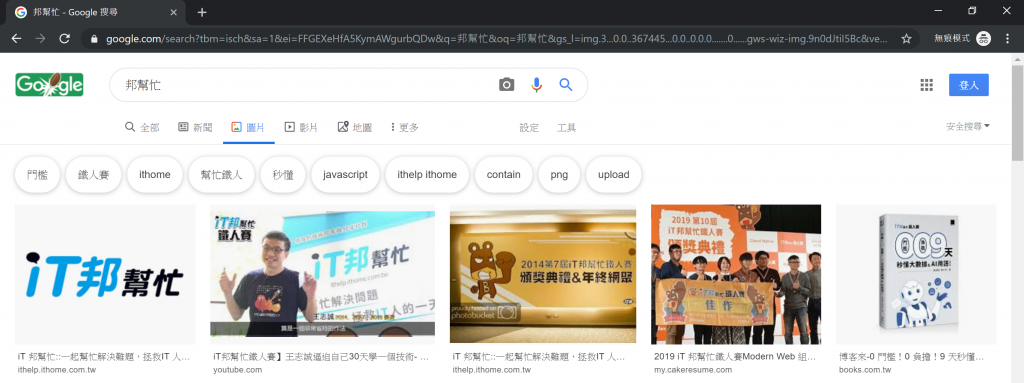
圖三、google 搜尋邦幫忙的圖片
而其中的網址 https://www.google.com/search?biw=1368&bih=721&tbm=isch&sa=1&ei=PTyEXce_IJG2mAWx7ogo&q=%E9%82%A6%E5%B9%AB%E5%BF%99以下略就是我們的目標。我們要做的東西是什麼呢?就是當使用者向 LINE 聊天機器人發送信息之後,聊天機器人根據信息內容,幫忙抓取 google 圖片搜尋的結果,並以ImageSendMessage回傳給使用者。所以在這一大串訊息裡面,到底什麼代表邦幫忙呢?讓我們來試著瞧瞧其中的玄機:
In [6]: search_url = 'https://www.google.com/search?biw=1368&bih=721&tbm=isch&sa=1&ei=PTyEXce_IJG2mAWx7ogo&q=%E9%82%A6%E5%B9%AB%E5%BF%99以下略'
In [7]: search_url.split('&')
Out[7]: ['https://www.google.com/search?biw=1368',
'bih=721',
'tbm=isch',
'sa=1',
'ei=PTyEXce_IJG2mAWx7ogo',
'q=%E9%82%A6%E5%B9%AB%E5%BF%99',
'oq=%E9%82%A6%E5%B9%AB%E5%BF%99',
'gs_l=img.12...0.0..40427...0.0..0.0.0.......0......gws-wiz-img.v2UXFgca_JQ',
'ved=0ahUKEwiH0seBsN7kAhURG6YKHTE3AgUQ4dUDCAc']
用技術含量較高的字眼來說,這叫做搜尋字串 (query string)➅,其實就是 google 幫你進行搜尋的時候所設定的一些條件。讓我試著來對這些結果做個粗淺的解釋。
['https://www.google.com/search?biw=1368',biw代指瀏覽器的寬(browser inner width)。 'bih=721', 'tbm=isch',isch就是圖片搜尋(image search)。 'sa=1', 'ei=PTyEXce_IJG2mAWx7ogo', 'q=%E9%82%A6%E5%B9%AB%E5%BF%99',q就是 query 的q。 'oq=%E9%82%A6%E5%B9%AB%E5%BF%99', 搞什麼的東西,結果我也只看得懂tbm跟q而已嘛。但這就夠了。我們已經知道,要讓 google 幫我們用關鍵字搜尋圖片,只要在網址列輸入'https://www.google.com/search?tbm=isch&q=你的關鍵字'就能搞定。但為什麼'q=%E9%82%A6%E5%B9%AB%E5%BF%99'這串奇異的符號代表我要搜尋邦幫忙呢?當然是因為編碼。但我怎麼知道要怎麼把邦幫忙轉換成 google 看得懂的編碼呢?別擔心,貼心的urllib早就幫你準備好道具了。但為什麼 Python這麼方便呢?當然是因為提供並建立這些 Python 資源的強者大大們太強了。不囉嗦,看一下程式碼。
In [8]: u = urllib.parse.urlparse(search_url)
print(u)
ParseResult(scheme='https', netloc='www.google.com', path='/search', params='', query='biw=1368&bih=721&tbm=isch&sa=1&ei=PTyEXce_IJG2mAWx7ogo&q=%E9%82%A6%E5%B9%AB%E5%BF%99&oq=%E9%82%A6%E5%B9%AB%E5%BF%99&gs_l=img.12...0.0..40427...0.0..0.0.0.......0......gws-wiz-img.v2UXFgca_JQ&ved=0ahUKEwiH0seBsN7kAhURG6YKHTE3AgUQ4dUDCAc', fragment='')
和剛才一樣的search_url,這次我們用專業的道具來解析解析。
In [9]: u[4]
Out[9]: 'biw=1368&bih=721&tbm=isch&sa=1&ei=PTyEXce_IJG2mAWx7ogo&q=%E9%82%A6%E5%B9%AB%E5%BF%99&oq=%E9%82%A6%E5%B9%AB%E5%BF%99&gs_l=img.12...0.0..40427...0.0..0.0.0.......0......gws-wiz-img.v2UXFgca_JQ&ved=0ahUKEwiH0seBsN7kAhURG6YKHTE3AgUQ4dUDCAc'
被我們用標籤u給貼上的是所謂的網址解析結果物件(ParseResult)。而u[4]網址解析結果物件其中的第四個項目就是搜尋字串。其他的項目也有分別代表一些相關訊息,有興趣的可以參考表一➆。
表一、網址解析結果物件的內容➆
| 屬性(attribute) | 位置(index) | 內容(value) |
|---|---|---|
| scheme | 0 | URL scheme specifier |
| netloc | 1 | network location part |
| path | 2 | hierarchical path |
| params | 3 | parameters for last path element |
| query | 4 | query component |
| fragment | 5 | fragment identifier |
不過字串還是太亂了,還是看不懂啊。那這樣呢?
In [10]: urllib.parse.parse_qs(u[4])
Out[10]: {'biw': ['1368'],
'bih': ['721'],
'tbm': ['isch'],
'sa': ['1'],
'ei': ['PTyEXce_IJG2mAWx7ogo'],
'q': ['邦幫忙'],
'oq': ['邦幫忙'],
'gs_l': ['img.12...0.0..40427...0.0..0.0.0.......0......gws-wiz-img.v2UXFgca_JQ'],
'ved': ['0ahUKEwiH0seBsN7kAhURG6YKHTE3AgUQ4dUDCAc']}
我看懂了!自從我服用urllib.parse.parse_qs之後,頭腦都靈光了很多,每次考試都考一百分。
反過來怎麼做呢?
In [11]: 我想找圖 = {'tbm': 'isch', 'q': '邦幫忙'}
urllib.parse.urlencode(我想找圖)
Out[11]: 'tbm=isch&q=%E9%82%A6%E5%B9%AB%E5%BF%99'
天啊,變成文字天書了。而且仔細一看,這段文字天書是不是跟 google 當初給我們的search_url有 87% 像?錯,再看仔細一點,根本是一個模子刻出來的啊。用這個字串放在https://www.google.com/search?後面當作網址,試試看它會帶我們到哪裡。https://www.google.com/search?tbm=isch&q=%E9%82%A6%E5%B9%AB%E5%BF%99
我的結果如圖四所示,不知道大家的一不一樣。
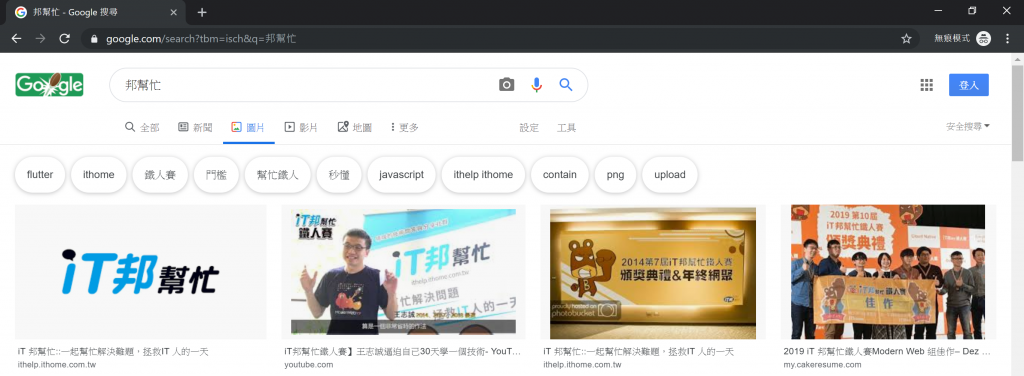
圖四、用我們製造出來的網址來搜尋
好啦,那太好了,我知道要怎麼請聊天機器人搜尋 google 並閱讀搜尋結果的頁面了:
In [12]: 我想找圖 = {'tbm': 'isch', 'q': '邦幫忙'}
url = f"https://www.google.com/search?{urllib.parse.urlencode(我想找圖)}/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
req = urllib.request.Request(url, headers = headers)
conn = urllib.request.urlopen(req)
data = conn.read()
print(data)
Out[12]: b'<!doctype html><html itemscope="" itemtype="http://schema.org/SearchResultsPage" lang="zh-TW"><head><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><meta content="origin" name="referrer"><title>…以下略
但走了這麼久,說了這麼多,我還是不知道圖片藏在哪裡啊?用conn.read()得到的,從開頭的<!doctype html>就表明了身分,是一個 HTML 5 的檔案內容。在這個檔案裡面要找圖,說難不難,說簡單好像也沒那麼簡單。我們先到瀏覽器去試試吧?一樣,先輸入剛才我們生產出來的新鮮網址:
https://www.google.com/search?tbm=isch&q=%E9%82%A6%E5%B9%AB%E5%BF%99
接著開啟瀏覽器的開發人員,如圖五紅框處。如果是 chrome 瀏覽器,快捷鍵 Ctrl + Shift + I,即可以看到如圖六的畫面。如果想調整開發人員工具的位置,就點擊右上角紅框處做選擇。
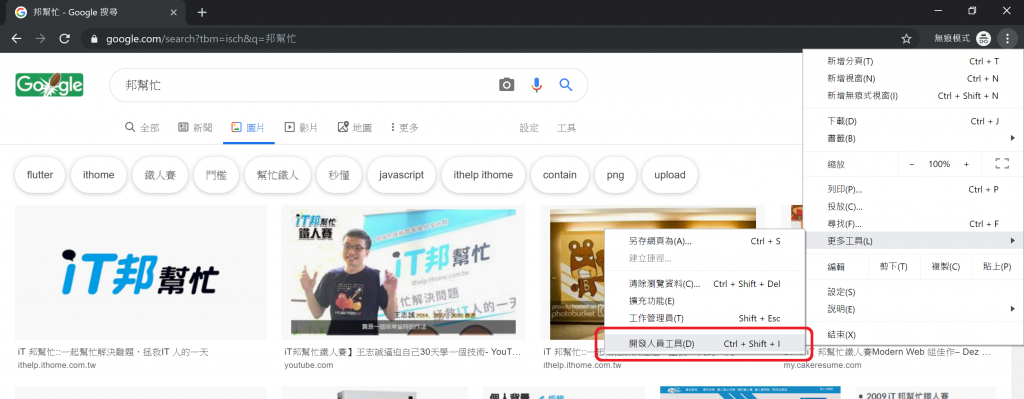
圖五、啟用開發人員工具
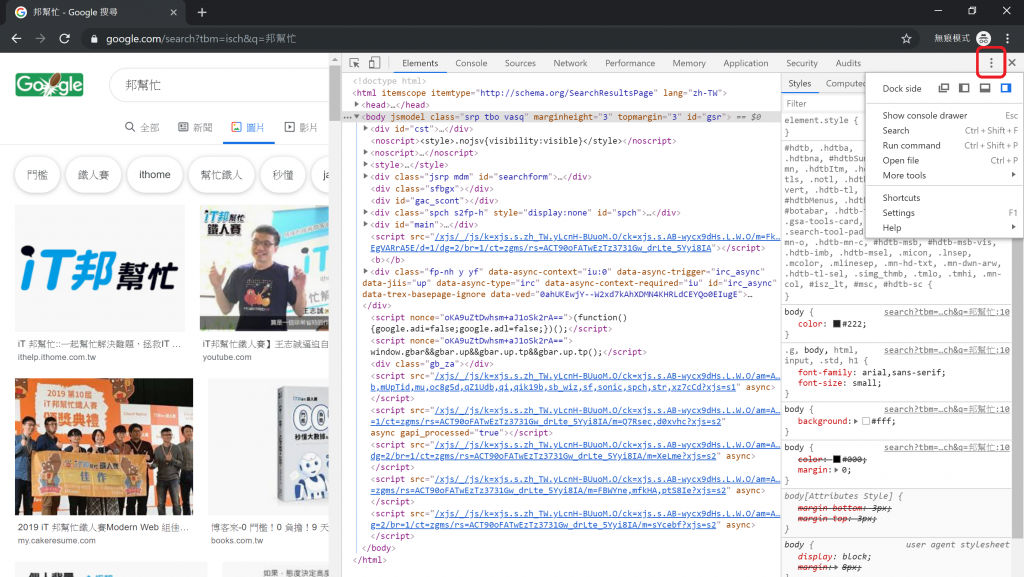
圖六、可利用開發人員工具選項,調整其位置
開啟開發人員工具要做什麼呢?第一個,開發人員工具看到的網頁原始碼就跟我們用conn.read()看到的是一樣的,而且還幫我們仔細的排版排好了。第二個,我們要用它來確認, google 幫我們搜尋到的圖片,究竟在 HTML 5 檔案內容的哪兒。怎麼做呢?當開發人員工具開啟,而且分頁設定在 Elements 的情況下,將滑鼠在各個不同的 element 之間移動,會看到相對應的區塊在瀏覽器內被標註了起來,如圖七。
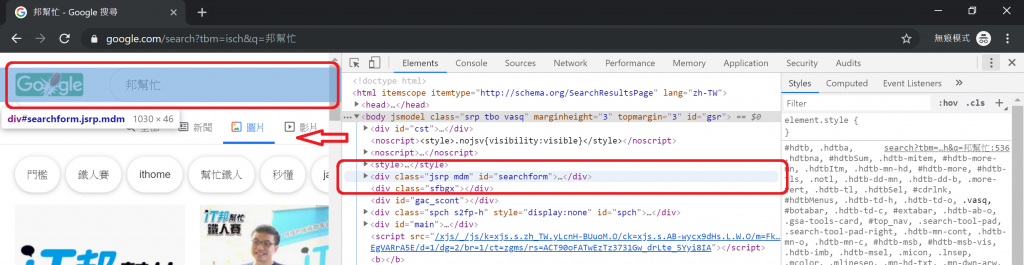
圖七、隨著滑鼠游標的移動而跟著改變標註的內容
HTML 5 是個像洋蔥一樣的層狀架構,找到大項目之後,按三角鍵把它剝開,如圖八紅框所示。基本上,第一個要剝的應該都是<div id="main">。
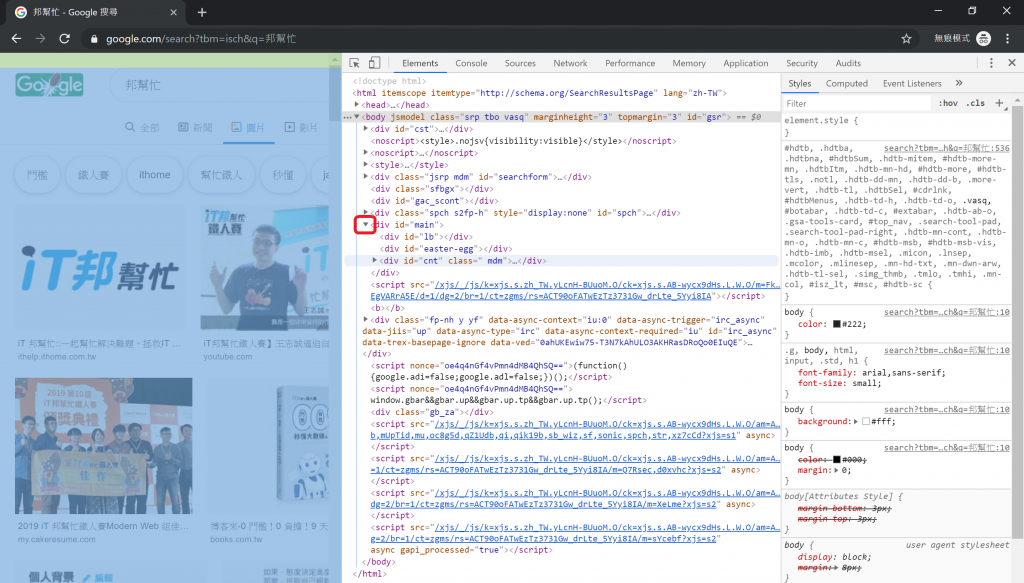
圖八、按三角鍵顯示裡層內容
就這樣重複剝開→尋找→剝開→尋找…以下略,的過程,可能會像圖九,最後應該會找到如圖十的結果。
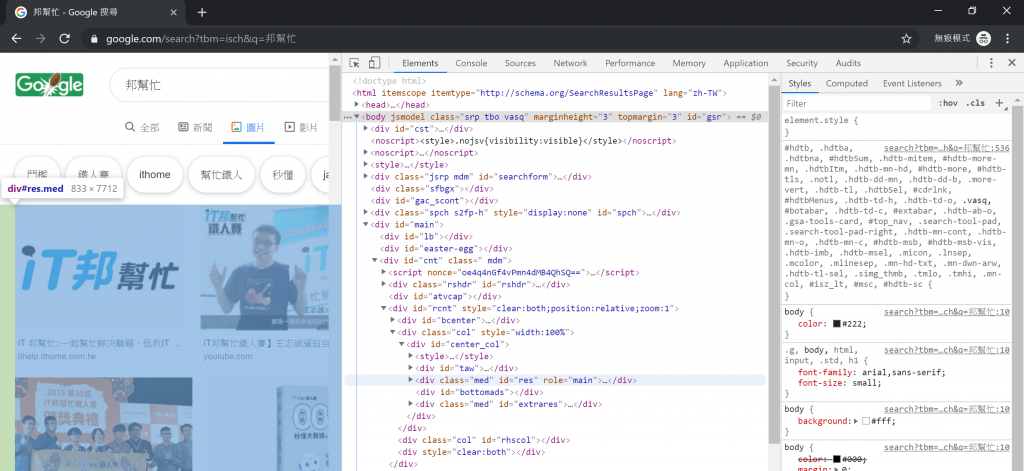
圖九、剝洋蔥剝洋蔥
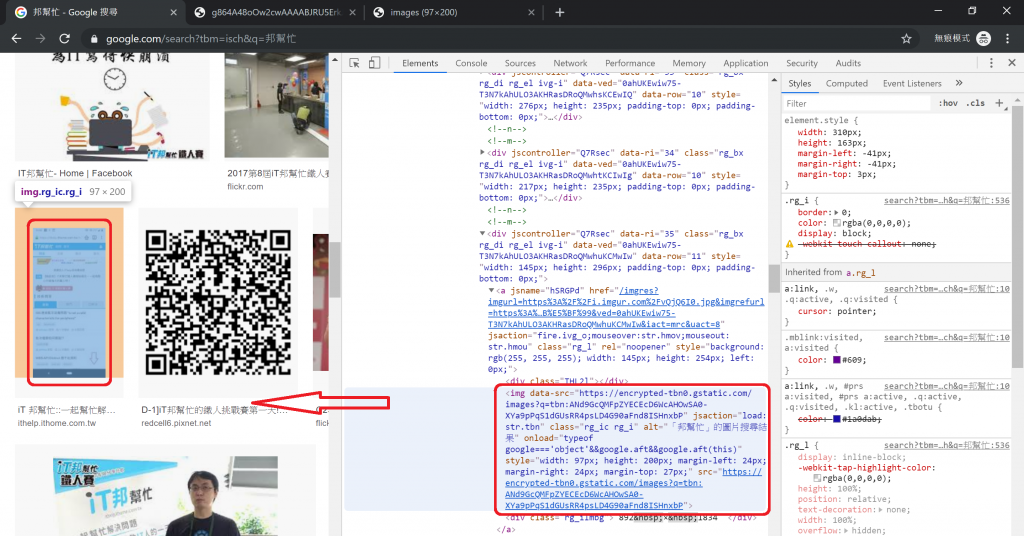
圖十、剝開到底了!
別問我為什麼找的不是第一個,而是藏在一堆圖片中的其中一個?說來慚愧,當然是因為這是以我目前的能力,可以處理的其中一個。
好啦,先別管我的能力如何,總而言之,<img data-src="這就是屬於圖片的 url" jsaction="以下略。還記的我們的正常表達(Regular Expressions)嗎?現在就要派上用場了,還不熟的可以翻到第 08 天參考一下。
In [13]: import re
In [14]: pattern = 'img data-src="\S*"'
img_list = []
for match in re.finditer(pattern, str(data)):
img_list.append(match.group())
pattern = 'img data-src="\S*"'pattern來找尋這就是屬於圖片的 url。\S*是什麼意思呢?\S是除了空白鍵之外的字元,後面加一個*,代表我們允許\S這種字元有任意數量個,可以是只有一個,也可以是有一百個。為什麼要這樣用呢?因為這就是屬於圖片的 url可能含有任意字元,而且字元的數量也不是固定的,唯一共通的一點,就是當中的字元都不屬於空白鍵。來看幾個我們找到的 url 吧:In [15]: img_list[:5]
Out[15]: ['img data-src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQMFpZYECEcD6WcAHOwSA0-XYa9pPqS1dGUsRR4psLD4G90aFnd8ISHnxbP"',
'img data-src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSVwDAVTRy7xfwQh-Zmp8sTw94r8NptdOA7k8cn1_NLXqOHHY3L"',
'img data-src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRLwTFvsjvYD2HZ-flSEuiFB_D7O8-tlg_K9ltHoYm5uP9LkZ0Y"',
'img data-src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTk_zc0NSyiaQrY7fXoJfzJRu-iDjhpFXWwo8Gi5g_36q07UIrc"',
'img data-src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ1F3sZMdEmEZAtIG3vHx9EYVDYJlklG2cnnOUzixFQNSbqP2aBjw"']
棒!看來我們找到方法來設計我們的聊天機器人了!
q_string = {'tbm': 'isch', 'q': event.message.text}
url = f"https://www.google.com/search?{urllib.parse.urlencode(q_string)}/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
req = urllib.request.Request(url, headers = headers)
conn = urllib.request.urlopen(req)
print('fetch conn finish')
pattern = 'img data-src="\S*"'
img_list = []
for match in re.finditer(pattern, str(conn.read())):
img_list.append(match.group()[14:-1])
random_img_url = img_list[random.randint(0, len(img_list)+1)]
print('fetch img url finish')
print(random_img_url)
line_bot_api.reply_message(
event.reply_token,
ImageSendMessage(
original_content_url=random_img_url,
preview_image_url=random_img_url
)
)
上面是整理過後,利用 google 找圖並回傳給使用者的程式碼。需要注意的一點是,上 google 查圖片不一定都會有結果,因此可以考慮用try、except這樣子的段落來處理。所謂的try、except段落我好像還沒解釋過。try、except常用在解決程式碼出錯的情況。
try:
第一段程式碼(比如用 google 找圖)
except:
第二段程式碼(比如學你說話)
Python 會先嘗試執行第一段程式碼,若執行順利,沒有出錯,就不會執行第二段程式碼。然而有些時候,程式碼因為種種原因,比如說設想不夠周到,沒辦法應對所有狀況,出了錯誤,就會執行第二段程式碼。以我們的例子,如果用 google 找圖,結果使用者輸入漢皇重色思傾國,御宇多年求不得。楊家有女初長成,養在深閨人未識。天生麗質難自棄,一朝選在君王側。回眸一笑百媚生,六宮粉黛無顏色。春寒賜浴華清池,溫泉水滑洗凝脂。侍兒扶起嬌無力,始是新承恩澤時。雲鬢花顏金步搖,芙蓉帳暖度春宵。春宵苦短日高起,從此君王不早朝。…以下略,google 找不到圖,沒辦法回傳訊息給使用者,這個時候就會執行第二段程式碼,也就是學你說話。
好啦,都沒有問題之後,就把我們新版的 LINE 聊天機器人推向 Heroku 吧!記得如果有換過 Python 的檔案名稱,記得也要進Procfile裡面做修改喔。
web: gunicorn 你要 Heroku 執行的 Python 檔案:app –preload
太棒了,忙碌的一天就到這裡結束。總結一下我們今天做了什麼吧:更加認識了 LINE 的應用程式編程介面、利用urllib瀏覽網址(看看這篇生猛的分享,是不是開始手癢想寫個刷你文三千的 LINE 聊天機器人呢?)、抓取網路上的資料、認識瀏覽器的開發人員工具、見識到了令人眼花撩亂的 HTML 5 文件,最後終於做出了我們的 google 抓圖機器人。Python 真是太神啦!相關的程式碼我已經放在 Github 上了,可以在這裡找到,有興趣的歡迎上去看看喔。另外,如果覺得我這次的文章有哪些地方沒有說明清楚的,或是需要改善的地方,也歡迎在下面留言,謝謝大家!
最後的最後,想聲明一下,我們的聊天機器人 Phoebe 可是個品味出眾的女孩,用 google 找圖實在是太不符合她的風格了。她要找圖,就要上 pixabay 找。讓我們用今天學過的技巧,試著幫她寫一個符合她個人特色的 LINE 聊天機器人吧:
from __future__ import unicode_literals
import os
from flask import Flask, request, abort
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, TextMessage, TextSendMessage, ImageSendMessage
import configparser
import urllib
import re
import random
app = Flask(__name__)
# LINE 聊天機器人的基本資料
config = configparser.ConfigParser()
config.read('config.ini')
line_bot_api = LineBotApi(config.get('line-bot', 'channel_access_token'))
handler = WebhookHandler(config.get('line-bot', 'channel_secret'))
# 接收 LINE 的資訊
@app.route("/callback", methods=['POST'])
def callback():
signature = request.headers['X-Line-Signature']
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
# 請 pixabay 幫我們找圖
@handler.add(MessageEvent, message=TextMessage)
def pixabay_isch(event):
if event.source.user_id != "Udeadbeefdeadbeefdeadbeefdeadbeef":
try:
url = f"https://pixabay.com/images/search/{urllib.parse.urlencode({'q':event.message.text})[2:]}/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
req = urllib.request.Request(url, headers = headers)
conn = urllib.request.urlopen(req)
print('fetch page finish')
pattern = 'img srcset="\S*\s\w*,'
img_list = []
for match in re.finditer(pattern, str(conn.read())):
img_list.append(match.group()[12:-3])
random_img_url = img_list[random.randint(0, len(img_list)+1)]
print('fetch img url finish')
print(random_img_url)
line_bot_api.reply_message(
event.reply_token,
ImageSendMessage(
original_content_url=random_img_url,
preview_image_url=random_img_url
)
)
# 如果找不到圖,就學你說話
except:
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=event.message.text)
)
pass
if __name__ == "__main__":
app.run()
想要認識 Phoebe 的,可以用下面的 QR code 找到她喔!謝謝大家!
圖十一、Phoebe 的 QRcode
➀ 發文以下略 KomicaWiki
➁ ImageSendMessage 使用說明
➂ 官方 LINE Developers Messaging API
➃ Python Software Foundation requests
➄ HTTP 頭欄位 wiki
➅ 搜尋字串(query string) wiki
➆ Python Software Foundation urllib.parse
註:對於此系列文有興趣的讀者,歡迎參考由此系列文擴編成書的 LINE Bot by Python,以及最新的系列文《賴田捕手:追加篇》
第 31 天 初始化 LINE BOT on Heroku
第 32 天 快速回覆 QuickReply 介紹
第 33 天 妥善運用 Heroku APP 暫存空間
第 34 天 妥善運用 LINE Notify 免費推播
第 35 天 製造 Deploy to Heroku 按鈕

